How to coordinate distributed services reliably? (Part 1)
TL;DR
The Saga Pattern keeps distributed workflows consistent by using compensating actions when steps fail. It can be done with Orchestration (commands from a central controller) or Choreography (services reacting to events) — often a mix of both works best.
In Part-2 of this article, we will explore how to go about rolling out your own Orchestrator without using any Orchestration tools
The Problem
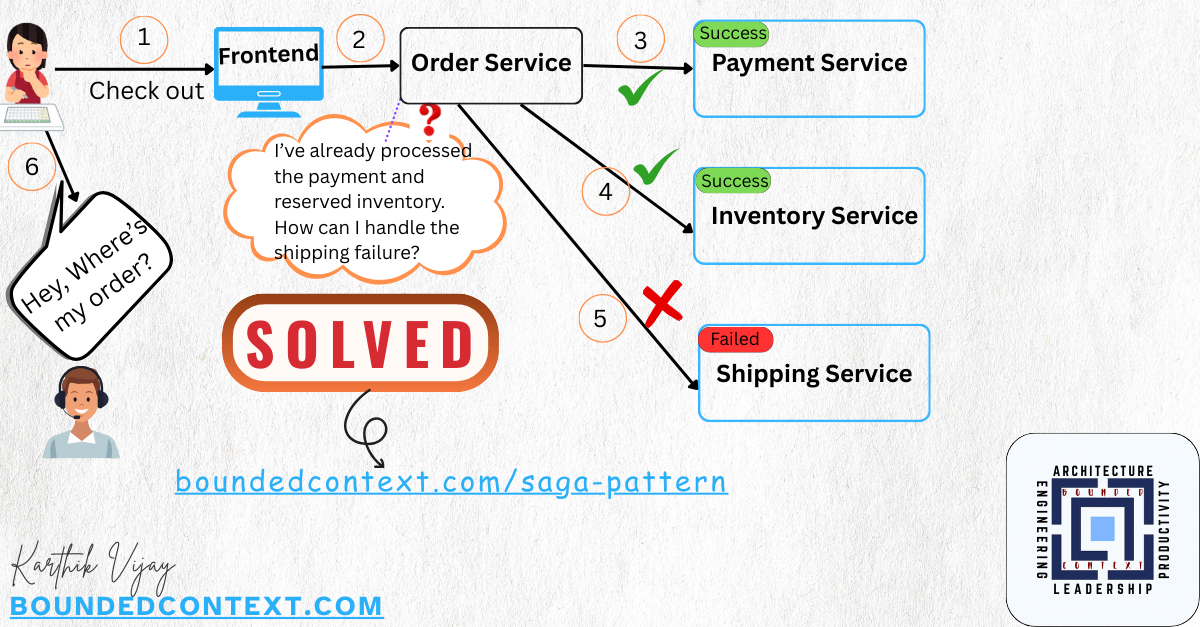
Coordinating multiple services in a distributed system is tricky. Each service in a distributed system performs its own task, and if one fails, the overall workflow can end up in an inconsistent state. There’s no easy way to automatically undo all the work that’s already been done.
In the picture above, imagine this scenario:
- ✅ Payment is successfully charged.
- ✅ Inventory is reserved.
- ❌ Shipping fails due to an unrecoverable error.
The result? The system is inconsistent:
- ✅ The customer was charged.
- ✅ Inventory is blocked.
- ❌ Customer never gets the item.
Solution
In the above Order workflow, coordination across services is essential to maintain consistency. Retries within individual services can help with transient errors, but they cannot resolve permanent failures—for example, if an item is damaged in transit. Since earlier steps have already succeeded, the correct approach is to perform compensating actions: refund the customer and update the inventory as necessary.
This is where the Saga pattern comes in.
A Saga breaks down a distributed workflow into a sequence of local transactions, each handled by a single service. Each transaction can succeed or fail independently. If a later step fails, the Saga ensures the system remains consistent by triggering compensating transactions to undo the effects of previously completed steps.
For the Order workflow, we are hoping to achieve something that would look like this:
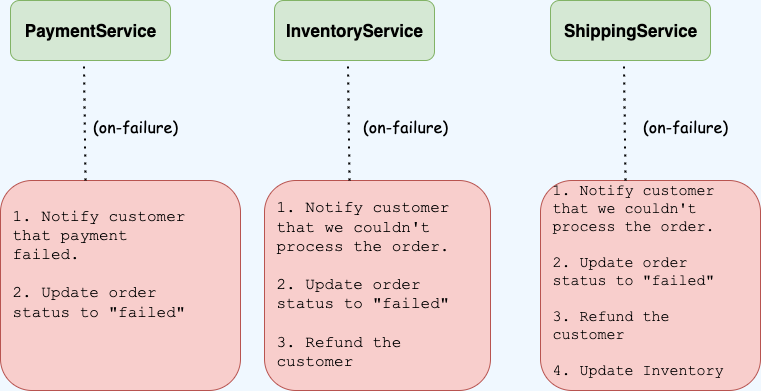
Compensating transactions are usually handled outside the individual service—let’s call this Global compensations. For example, it doesn’t make sense for the InventoryService to refund a customer if an inventory reservation fails, since managing payments is outside the bounded context of the InventoryService.
In contrast, a Local compensation happens within the same service. For instance, if a reservation fails, the InventoryService can simply release the reserved items. Local compensations are easier to manage since the service has full control over its own state.
Orchestration vs Choreography
There`s two variations of the Saga pattern.
- Orchestrated Saga: Command-based — a central orchestrator directs each step and triggers compensations when needed. Can be synchronous or asynchronous.
- Choreographed Saga: Event-based & inherently asynchronous — services react to events, which signal that something has already happened, and trigger compensations through event-driven logic.
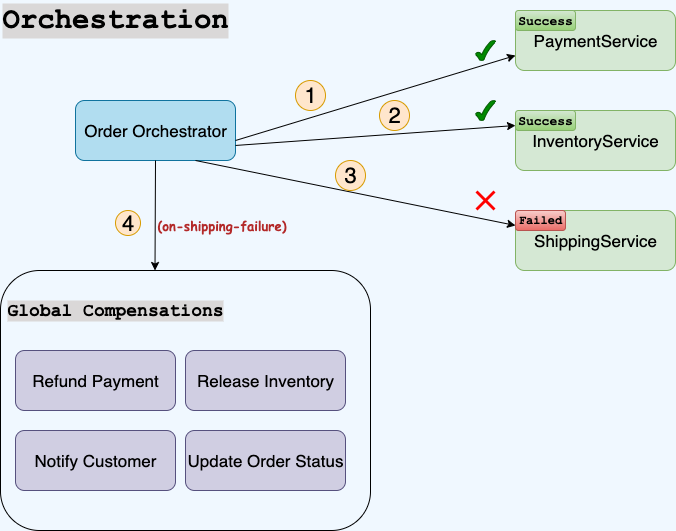
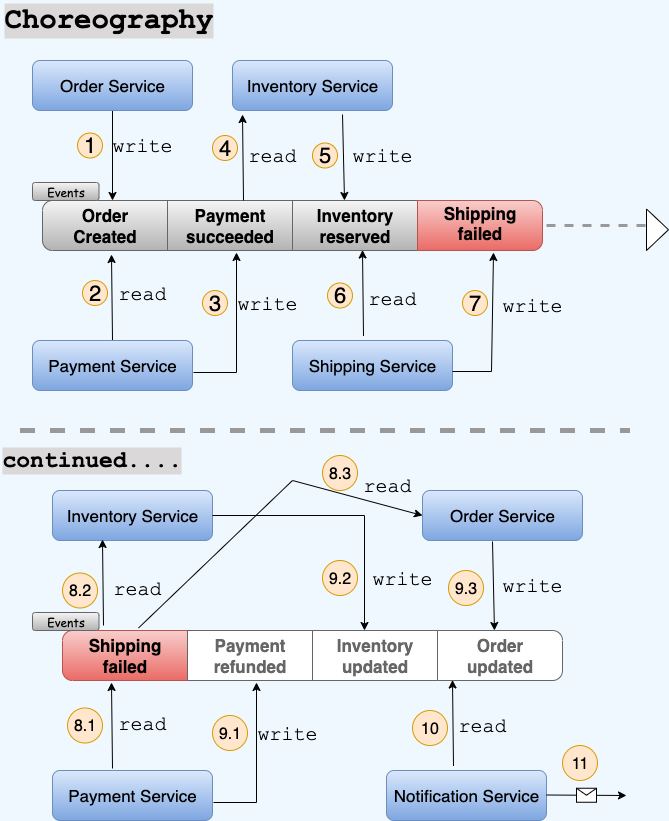
Comparison Table
| Feature | Orchestration | Choreography |
|---|---|---|
| Control | Centralized - Command driven | Decentralized - Event-driven |
| Message style | Do this thing (Command) | This thing just happened (Event) |
| Trigger Example | "ChargePayment" command sent by orchestrator | "OrderCreated" event emitted by OrderService |
| Communication style | Synchronous or Asynchronous | Asynchronous |
| Complexity | Easier to visualise and reason about the flow | Flow emerges across services and can be hard to track without Monitoring & Distributed Tracing |
| Failure handling | Easier to handle global compensations | Slightly harder to handle global compensations |
| Use case | Step-by-step workflows | Event propagation & async tasks |
| Common use case | Business-critical flows (e.g., order fulfillment) | High-scale side-effects (e.g., likes/notifications) |
👉 High-scale side-effects = lots of downstream actions triggered by a single fact, usually not core to the transaction, often fan-out to many services.
The saga doesn’t have to be strictly one or the other—it can be a mix, using orchestration for critical, dependent steps while leveraging choreography for independent operations. The ideal scenario for choreographed event-driven communication is when the message leaves the bounded context of the current domain and the domain doesn’t need to track what happens next to the message. For example, in an Order workflow, this could be notifying a third-party analytics system.
Orchestration tools
👉 If your orchestration needs go beyond one-off use cases and you require a comprehensive enterprise solution with built-in monitoring, workflow management, and more, there are several open-source and commercial orchestration tools to choose from, instead of hand-crafting the orchestrator yourself:
Netflix Conductor , as it used to be called, had been the tool of choice for orchestrating services over the years. However, Netflix has stopped maintaining the project in an official capacity as of December 2023. Conductor OSS still remains popular as a continuation/fork of Netflix Conductor.
👉 If you are in AWS and you just need a simple workflow with retries and failure management, you could consider using AWS Step Functions
In Part-2 of this article, we will explore how to go about rolling out your own Orchestrator without using any of the above tools.