Idempotency Keys: How to Prevent Duplicate API Requests?

TL;DR
Duplicate API requests often come from retries, double-clicks, or flaky networks. Prevent them with client-side locking/debouncing and server-side idempotency keys. Choose the right storage strategy (response, resource, or metadata), apply TTLs, and keep your APIs safe from double orders or payments.
The Problem
Ever clicked Submit twice and ended up with a double order? Or been charged twice for the same payment? Duplicate requests like these happen more often than you’d expect — and they can quickly erode data integrity and user trust. Here’s how to stop them for good.
Solution
To prevent duplicate orders or requests, you need a combination of client-side and server-side strategies that handle different causes of duplication:
👉 Client Side Locking
- Prevents multiple submissions from the same user/session.
- Example: Disable the Submit button while the request is in progress.
- Protects against accidental double-clicks or rapid repeated actions.
👉 Client Side Debouncing
- Prevents multiple requests from being sent in quick succession.
- Example: Typeahead search fields, sliders, or toggles — send the request only after the user pauses for say 300ms.
- Helps reduce server load and improves user experience for frequent interactions.
👉 Server Side Idempotency Key
- Each request carries a unique key generated by the client (e.g., a UUID).
- The server stores the key with the result of the request.
- If the client retries the same request (for example, after a timeout), the server returns the previous response instead of creating a duplicate.
- Ensures safe retries and network-resilient behavior for individual devices.
Client side locking and debouncing techniques are fairly straightforward to implement. For the rest of the article, we will focus on server-side idempotency keys and how they can help prevent duplicates.
Idempotency Key Workflow: Handling New vs Duplicate Requests
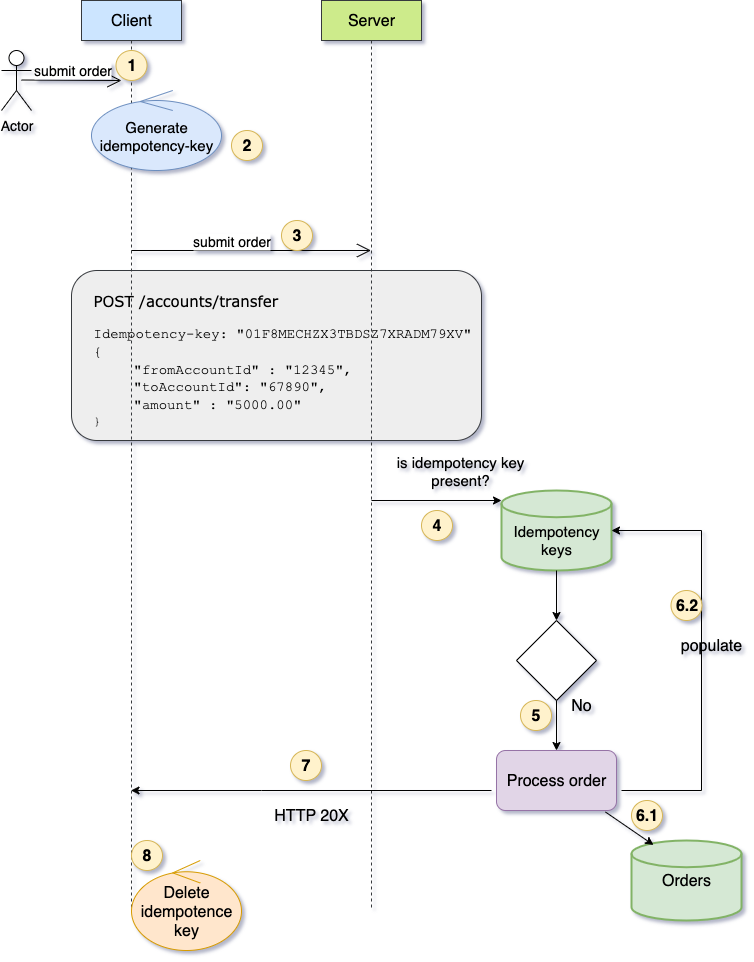
Scenario 1 - Happy path - Idempotency key not found in server
In this case, the server does not find the client-generated idempotency key in its records. It therefore treats the request as a new, non-duplicate submission and processes the order normally.
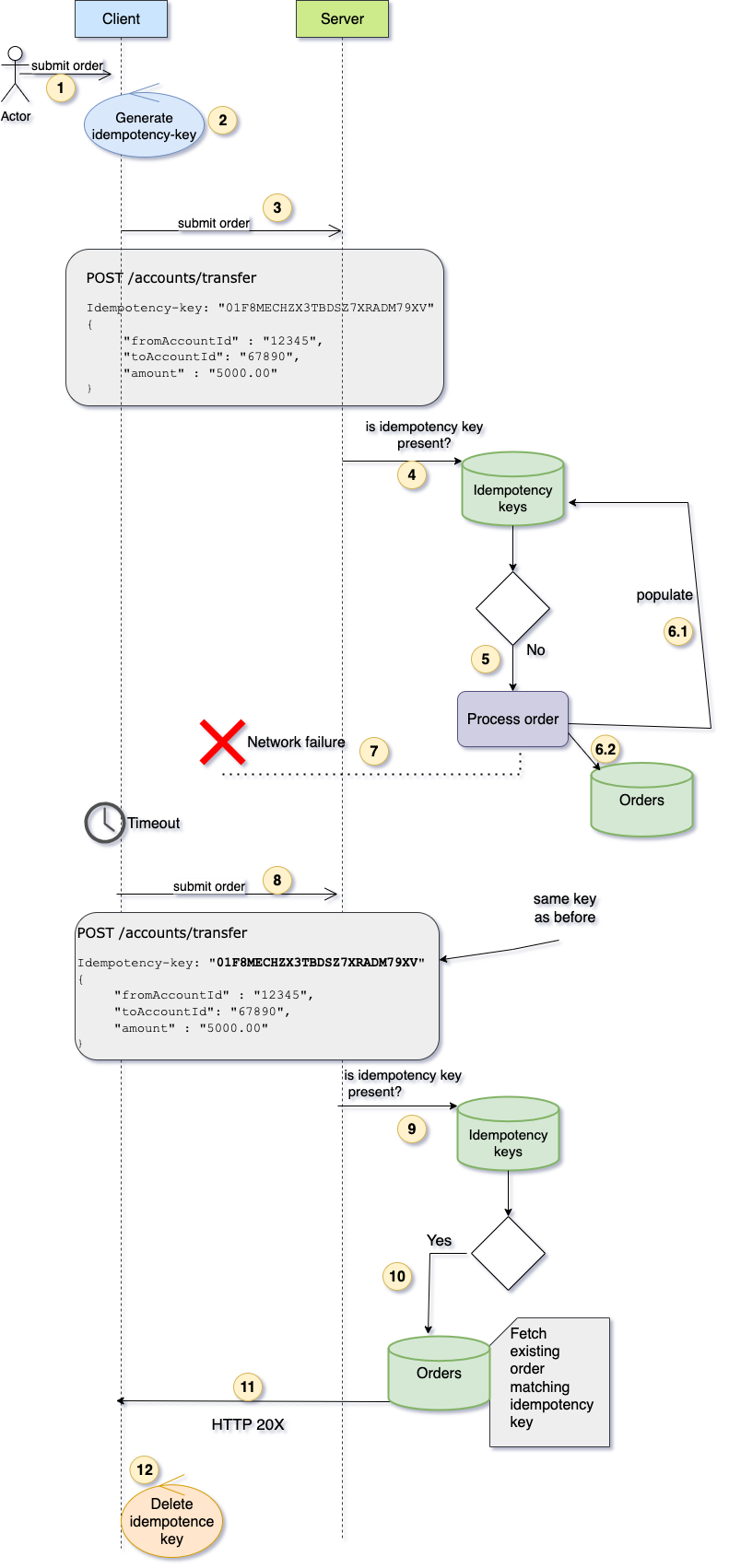
Scenario 2 - Duplicate request
In this scenario, the client’s original request was successfully processed by the server, but a network failure prevented the response from reaching the client. The client timed out and resent the same request using the same idempotency key. The server recognises the key, returns a successful response, and ensures that no duplicate order is created.
Idempotency keys table design
Option 1 : Key -> Full response
Option 1 stores the full response of a request along with the HTTP status code. This allows the server to replay the exact response if a client retries the same request using the idempotency key. It is particularly useful for operations with side effects or non-deterministic results, such as creating orders or processing payments, because storing the full response ensures that the server can safely prevent duplicates while returning exactly what the client expects.
"idempotency_key" : "u123456:01ARZ3NDEKTSV4RRFFQ69G5FAV" // key
{ //value
"user_id": "u123456",
"response_body": { "orderId": 101, "item": "Laptop", "quantity": 1 .... },
"status_code": 201,
"created_at": "2025-09-22T10:01:16Z",
"expires_at": "2025-09-23T10:01:16Z"
}
Pros
- Easy to implement.
- Works well for retries — simply return the stored response.
Cons
- Full response is stored → could grow large for complex payloads.
Option 2: Key -> Resource Reference
Option 2 tracks the resource reference created by a request, such as an order or payment ID, instead of storing the full response. The server uses the idempotency key to check if the resource was already created and can return the same result without creating a duplicate. This approach is lightweight because it avoids storing large responses, while still allowing the server to safely prevent duplicates and reconstruct the response from the existing resource.
"idempotency_key" : "u123456:01ARZ3NDEKTSV4RRFFQ69G5FAV" // key
{ // value
"user_id": "u123456",
"resource_type": "order", // e.g., order, payment, invoice
"resource_id": 101, // ID of the created resource
"created_at": "2025-09-22T10:01:16Z",
"expires_at": "2025-09-23T10:01:16Z"
}
Pros
- Lightweight: only stores a reference, not the full response.
- Decouples idempotency tracking from business data.
- Supports multiple resource types in a single table.
Cons
- Requires an extra lookup to fetch the actual resource.
- Server must reconstruct the response from the resource table.
Option 3: Minimal Key → Metadata
Option 3 is about storing only that the request was received, without storing the full response or resource ID. The server does not store the resource — it only tracks that a client already sent this key. This is ideal for deterministic operations, where the response can be recomputed from the request itself.
Since the server does not store the original request or response, it cannot independently verify that a retry contains the same payload. For this reason, a request hash is strongly recommended. The hash ensures that the incoming retry matches the original request, preventing accidental or malicious payload changes while still maintaining idempotency.
"idempotency_key" : "u123456:01ARZ3NDEKTSV4RRFFQ69G5FAV" // key
{ // value
"user_id": "u123456", // authenticated user
"request_hash": "abc123def456", // hash of the original request payload
"created_at": "2025-09-22T10:01:16Z",
"expires_at": "2025-09-23T10:01:16Z"
}
Pros
- Extremely lightweight; minimal storage overhead.
- High throughput and low latency.
- Good for deterministic operations where response can be reconstructed.
- Request hash ensures payload consistency on retries.
Cons
- Cannot store the actual response; server must reconstruct it.
- Not suitable for operations with side effects or non-deterministic results.
Comparison of Idempotency Options
| Feature / Option | Option 1: Full Response | Option 2: Resource Reference | Option 3: Minimal Metadata |
|---|---|---|---|
| What is stored | Full response + HTTP status code | Resource type + ID | Marker only (user_id, timestamps, optional request hash) |
| Original request stored? | No | No | No |
| Can reconstruct response safely? | Yes, from stored response | Yes, from existing resource | Only if request hash matches |
| Duplicates prevented? | Yes | Yes | Yes |
| Request hash required? | Optional (for validation/observability) | Optional (for validation/observability) | Strongly recommended |
| Payload changes on retry | Original response returned; new payload ignored | Existing resource returned; new payload ignored | Risk of inconsistent result without request hash |
| Storage overhead | High | Medium | Very low |
| Use case | Non-deterministic / side-effectful operations (orders, payments) | Side-effectful operations where resource reconstruction suffices | Deterministic operations where response can be recomputed from request |
| Pros | Exact response replay; safe for any side effect | Lightweight; can reconstruct response; safe for side effects | Extremely lightweight; high throughput; request hash ensures payload consistency; good for deterministic operations |
| Cons | Storage can grow large for complex responses | Must reconstruct response; payload differences ignored | Cannot store actual response; must validate payload with request hash; not suitable for side-effectful or non-deterministic operations |
Best Practices
1. Idempontency Key Format: ULID vs UUID
UUID (Universally Unique Identifier)
- Widely used, standardized, easy to generate in most languages.
- Older UUID versions (like v4) are purely random and not time-sortable. UUIDv7 encodes a timestamp, making it time-sortable — but correct chronological ordering only works when the UUIDs are compared in binary form, not as their standard string representation with dashes.
ULID (Universally Unique Lexicographically Sortable Identifier)
- Monotonic and time-sortable → easier for logging, debugging, and database indexing.
- Compact and human-readable
Best Practice:
- Either works for idempotency, but ULIDs are generally preferred if you want sortable keys.
2. TTL (Time-to-Live)
- Idempotency keys don’t need to live forever.
- Set up a Time to Live (TTL) on each of the idempotency keys depending on the business context and use case. It is very rare that TTL would need to be more than a few hours for most cases.
- Setting up a reasonable TTL prevents the idempotency key table from growing indefinitely.
3. Discard key after successful response
- Once the client receives a confirmed success (or failure) response, the key has served its purpose.
- Delete or discard it on the client side.
- Do not reuse keys for different requests — each logical operation must have a unique key.
4. Per-Request Uniqueness
- Generate a new idempotency key for every logical operation.
- Never generate a new key for a retry — that defeats idempotency.
- Always send the same key if the client retries due to network timeouts or errors.