Why should you run chaos tests?

TL;DR
Chaos testing evaluates how systems respond to failures. Chaos testing doesn’t have to be scary - you don’t necessarily need to shut down live prod servers like what Netflix or Amazon does. Start simple with deterministic chaos tests in CI/CD or staging, and run your system dependencies like third party apis, databases or Kafka in Containers so tests are safe and isolated. Simulating simple, controlled failures like shutting down or slowing down a database, nuking connections, adding latency to a third party api can reveal hidden flaws in your system and build confidence in reliability.
What is chaos testing?
Chaos testing is the practice of deliberately introducing controlled failures into a system to validate that it behaves reliably under unexpected conditions. Instead of assuming that your systems will handle outages gracefully, chaos testing forces those scenarios to happen — on your terms.
At its core, chaos testing is about asking:
- What happens if this dependency goes down?
- Can the system still serve users if network latency spikes?
- Does your failover strategy actually work, or just look good on paper?
Chaos Engineering as a discipline has been around for a long time. Netflix popularized the idea with their open source tool Chaos Monkey
Deterministic vs non deterministic chaos
Chaos Monkey is non deterministic by design. It introduces random failures to test overall system resilience, so you can’t repeat the exact scenarios or measure precise outcomes. Deterministic chaos, on the other hand, uses planned, repeatable failures that are easy to automate, track, and debug.
Start with deterministic chaos: You don’t conduct fire drills by setting the whole building ablaze – begin with controlled flames first. For the average organisation, this step alone can go a long way toward strengthening resilience. Deterministic chaos tests would be focus for the rest of this article.
| Feature | Deterministic Chaos | Non-Deterministic Chaos |
|---|---|---|
| Goal | Validate system behavior against expected outcomes | Build confidence in overall resilience |
| Analogy | Fire drill in a single room at 10 AM every Monday | A random fire alarm going off somewhere in the building any day/time of the week |
| Example | Inject 3s latency to the payments API for exactly 5 minutes | Randomly slow down some random API calls at unpredictable times |
| Failure Pattern | Scripted, repeatable | Random, unpredictable |
| CI/CD Suitability | High - can automate and integrate | Low - hard to reproduce in pipeline |
| Metrics | Precise and repeatable - latency, failover time, error rates | Broad trends only - outcome varies each run |
| Tools | Docker, Toxiproxy, Wiremock, Gremlin ... | Chaos Monkey, AWS Fault Injection Service, Gremlin ... |
How to run deterministic chaos tests?
Deterministic chaos tests can be incorporated into your CI pipeline without expensive tools. Docker, and optionally Toxiproxy, are usually sufficient and will do the job fine for free for the average app that needs to be chaos tested.
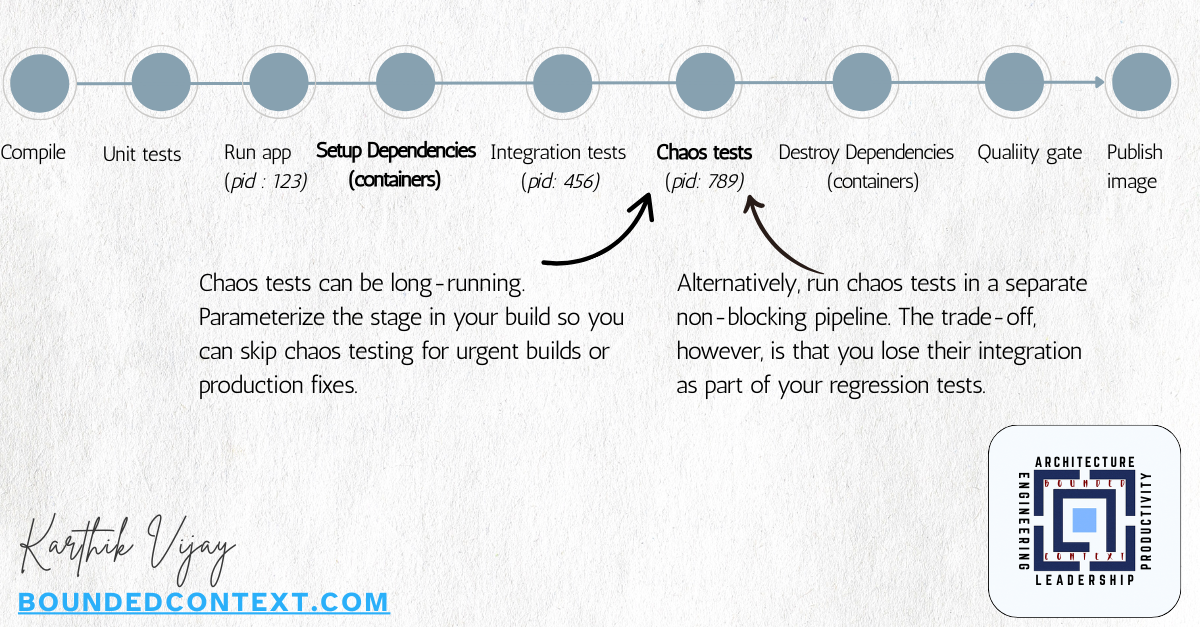
- Run Chaos tests in a separate process from the running app It may sound obvious, but the chaos injector should run in a separate process from the application. This separation allows you to start, stop, or even crash the injector without affecting the app itself.
- Use Containers to Control Dependencies Run dependencies such as databases, kafka brokers, third party apis in Docker containers. This allows you to preload mock data and stop or restart services safely as part of the chaos tests.
- Simulate Real-World Failures Introduce conditions such as service shutdowns, latency, or network disruptions to observe how the system behaves under stress.
- Leverage Chaos Testing Tools Tools like Toxiproxy make it easier to simulate outages. They can introduce latency, enforce rate limits, or bring services down without touching shared infrastructure.
- Assert Behaviour in Chaos Tests For each chaos test, you can verify that specific behaviours occur. For example, if a Kafka consumer must write to the database before committing the offset, you could shut down the database and ensure the Kafka message remains unprocessed in the topic.
- Keep CI/CD Pipelines Flexible Chaos tests improve confidence but can slow urgent production fixes. Use a build parameter or toggle to run them by default, with an option to skip when speed is critical.
An example of a deterministic chaos test
Let’s say your application consumes messages from a Kafka topic and writes the data to the database.
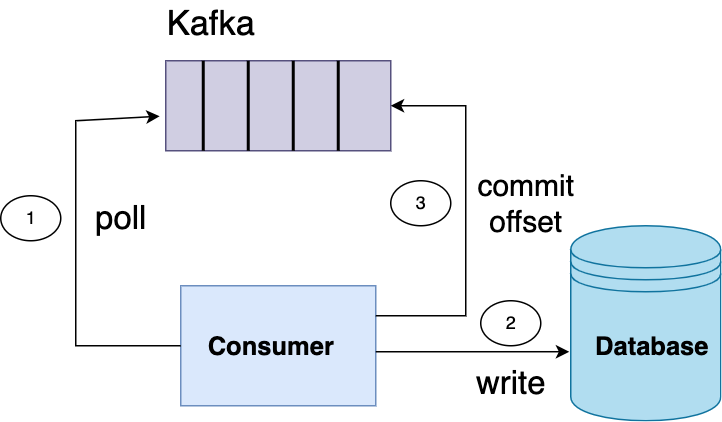
A simple chaos test you could write would be to shut down your database while your app is running and verify that no Kafka messages are lost during processing
# Application Logic
def process_message(message):
while True:
try:
write_to_database(message) # attempt DB write
commit_offset(message) # commit only on success
return True
except DatabaseError:
wait_and_retry() # app retry logic
# Chaos Test Logic
# Step 1: Inject deterministic failure
shutdown_database() # database goes down at a known time
# Step 2: Assert that the kafka offset was not committed
assert not offset_committed(some_message) # offset should NOT be committed
# Step 3: Start the database
start_database()
# Step 4 : Assert that the kafka offset was committed
assert offset_committed(some_message) # offset should have been committed
assert record in database # database should have the new record
Bonus example
Here’s another example. In the below design, let’s assume that the API already writes to a database currently, and Kafka has been bolted on later as an afterthought to publish events. This is quite a common and easy mistake to make. If the publishing to Kafka fails silently, the database may be updated but downstream systems aren’t — creating a hidden inconsistency. You obviously don’t need chaos testing to notice this flaw; experienced eyes will spot it rather easily. But chaos testing makes it undeniable by demonstrating how the system behaves under failure conditions.
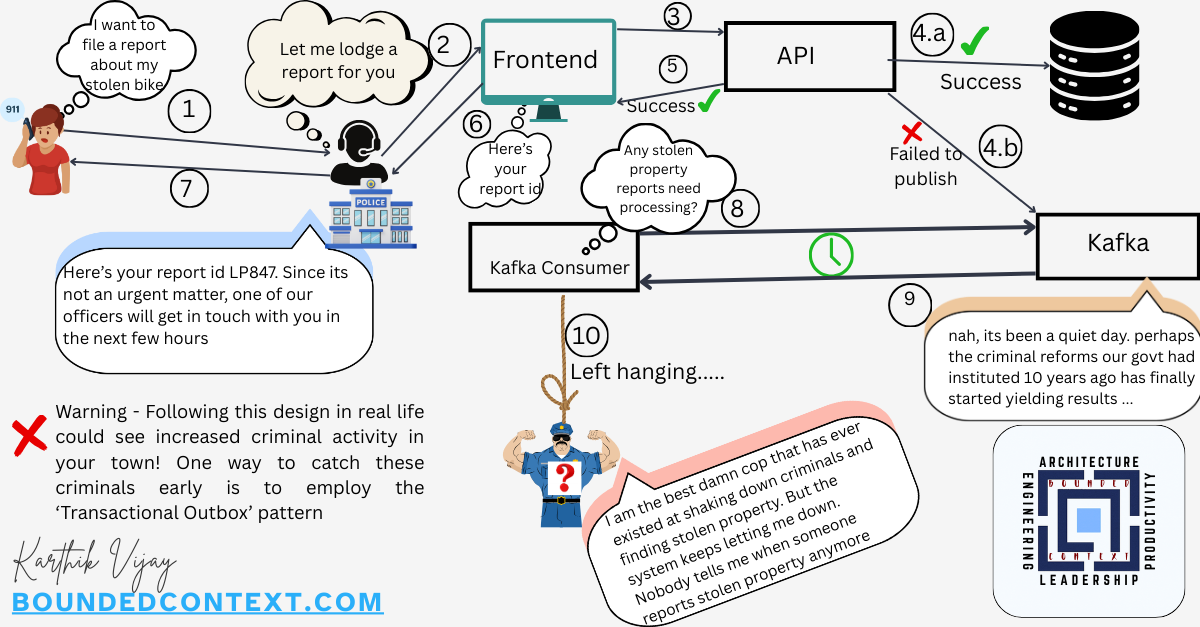
What are some of the deterministic chaos tests can you run for the above use case? Can you identify opportunities to improve the overall system reslience?
- Kafka failure: How does the api behave if the database write succeeds but the event cannot be published to Kafka? Is the overall system still in a consistent state?
- Database failure: If the database write fails, does the API still attempt to publish to Kafka? What is the observable behavior for the client?
- Kafka broker outages: What is the maximum number of Kafka brokers that can be down while still allowing the event to be successfully published?
- Transient Kafka downtime: If Kafka is temporarily unavailable (for example, a few seconds), does the API retry, and how many times? How does this affect overall request latency?
- Database recovery & throttling: If the database is slow or recovering, how does the API behave? Does it avoid overwhelming the database in this state? (Circuit breaker?)
- End-to-end flow under load: Simulate a combination of slow database responses and intermittent Kafka failures to see how the system behaves under realistic stress conditions.
Why don't most orgs run chaos tests?
- Chaos testing sounds scary - randomly killing prod servers can have unpredictable consequences.
- Chaos testing is hard; We don’t have the budget, time or expertise.
- We don't need it; We are not Netflix or Amazon
- There's no point; We already know our system is bad; Why make it worse?
These concerns are not entirely invalid or misplaced. Many of us hear the term Chaos testingand we immediately picture Chaos Monkey running amok and randomly killing prod servers — which sounds terrifying. The good news: you don’t have to start there. Deterministic chaos tests in CI/CD pipelines or staging let you safely and repeatedly test failures, building confidence in your system’s resilience without ever risking real users.